
Transformer

1 | d_model = 512 # 词嵌入 Embedding 的维度 |
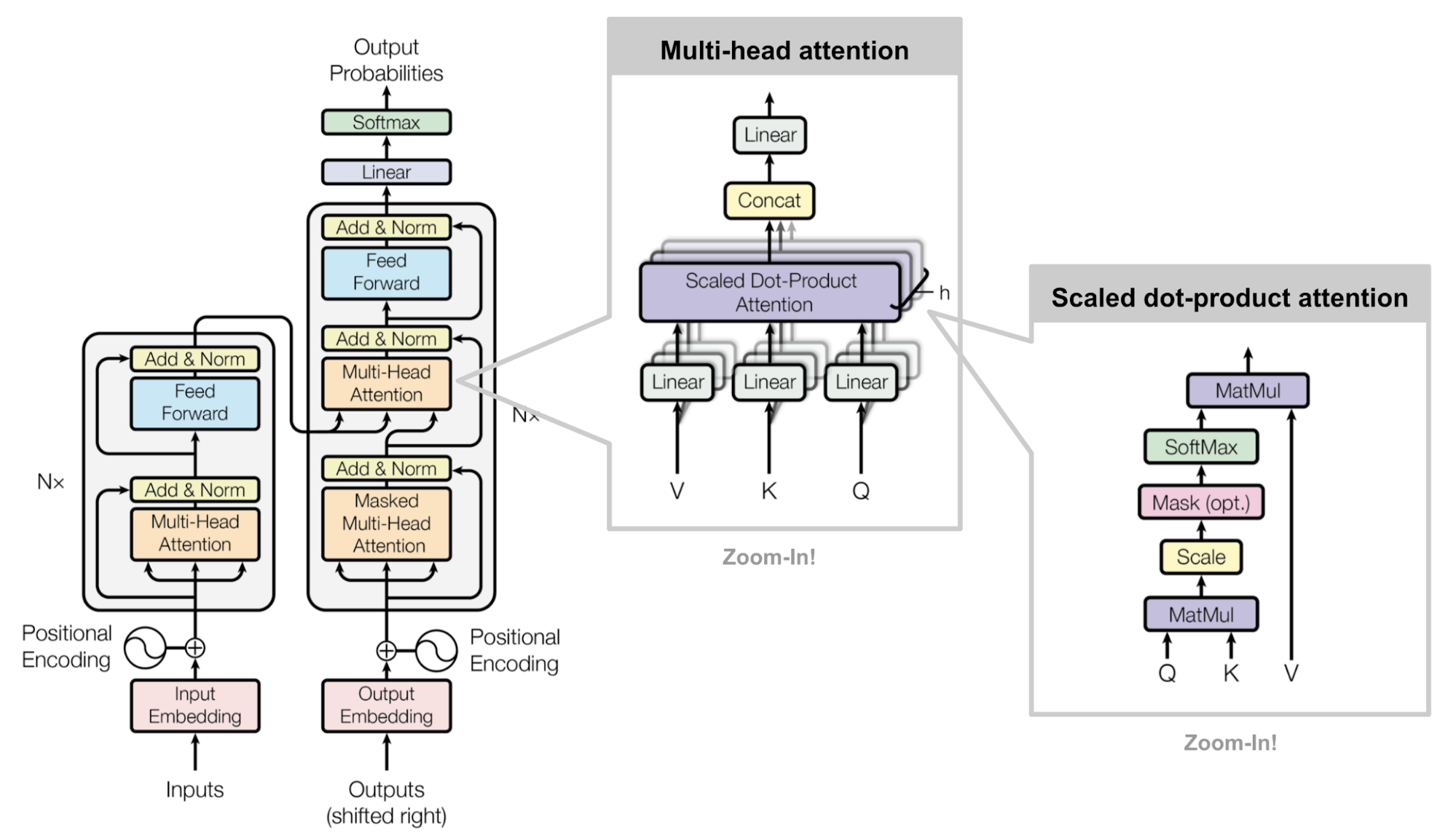
一、 Encoder
编码器由𝑁层模块堆叠而成(设置n_layers=6)。序列数据首先经过词嵌入(embedding)变换为词向量(长度为d_model=512),与位置编码(positional encoding)相加后作为输入。
1 | class Encoder(nn.Module): |
为何在获取输入词向量之后需要对矩阵乘以embedding size的开方?意义是什么?
Transformer 中输入的词嵌入(embedding)会做:
因为 embedding 用 Xavier 初始化时方差为 1/EmbeddingSize,尺度太小。乘以EmbeddingSize后方差变为 1,使 embedding 与位置编码处于同一量级,提高注意力与前几层网络的训练稳定性,利于收敛。
1. positional encoding : Sinusoidal functions
1 | class PositionalEncoding(nn.Module): |
自注意力机制无法捕捉位置信息,这是因为其计算注意力时的无序性,导致打乱任意顺序的序列其每个对应位置会得到相同的结果。通过引入位置编码把位置信息直接编码到输入序列中。
pos: token在序列中的位置(0, 1, 2, …);i: 该token位置编码向量中的第i维(0 <= i <= d_model/2-1);d_model: 编码向量的总维度(在原始论文中为512)。
pros:
(1)它能用来表示一个token在序列中的绝对位置(低维,i小,变化缓慢的正弦波)
(2)在序列长度不同的情况下,不同序列中token的相对位置/距离也要保持一致(高维,i大,变化迅速的正弦波)
(3)唯一性:得益于频率的几何级数变化,在实际序列长度(eg.1000)内,每个pos都有独特的位置编码
(4)线性关系: 对于任何固定的偏移量 k,PE(pos+k) 可以被表示为 PE(pos) 的一个线性变换。
(5)可外推到未见长序列
cons:
(1)外推性能弱: 当推理时遇见显著长于训练长度的序列时,性能急剧下降
(2)对于非常长的序列,低频维度(i 较小的维度)的变化非常缓慢
其他位置编码
| 技术 | 类型 | 优点 | 缺点 |
|---|---|---|---|
| Learned Positional Embedding | 绝对 | 可学习、表现好 | 不能外推到更长序列 |
| Rotary Position Embedding(RoPE) | 相对 | GPT-3.5 / Llama 使用,效果强、外推性好,将位置信息作为乘性旋转注入查询和键。 | 复杂一些 |
| ALiBi | 相对 | 训练时支持长序列,推理可无限延长 | 非周期,长距时信息衰减过快 |
2. 占位符padding的操作
由于输入序列中可能存在占位符等没有意义的token,因此使用get_attn_pad_mask函数生成注意力mask,在计算注意力时将这些位置置零。实现过程:首先找出这些位置(标记为1),并在后续的注意力计算中将这些位置赋予一个较大的负值(如-1𝑒9),这样经过softmax函数后该位置就趋近于0。
1 | def get_attn_pad_mask(seq_q, seq_k): # seq_q: [batch_size, seq_len] ,seq_k: [batch_size, seq_len] |
在计算attention score的时候如何对padding做mask操作?
mask 操作:
其中 mask 的值:
- padding 位置:1
- 非 padding:0
Padding token 的 embedding 一般设置为 0,Future tokens(在 causal mask 中)embedding 和 Q/K/V 都正常计算。
Mask 会在 attention score 上把不允许的位置设为 -1e9,再将这个 Masked 分数矩阵送入 Softmax。Softmax 后 padding 的概率变成 0,完全不影响结果。
3. attention
1 | class MultiHeadedAttention(nn.Module): |

- 为什么在进行softmax之前需要对attention进行scaled(÷√dk)?
这取决于softmax函数的特性:softmax函数将输入的每一行规范化为概率分布,由于其对较大的数值敏感,会导致数值较大的位置更有可能趋近于1,使得其他位置均趋近于0,会输出近似one-hot编码的形式,导致梯度消失,无法训练。
那么至于为什么需要用维度开根号,假设向量Q,K满足各分量独立同分布,均值为0,方差为1,则其点乘向量的均值为0,方差为dk,为保持 score 的方差稳定,需要除以√dk,使 score 的方差回到 1。
除了对attention进行scaled(÷√dk),还有什么方法可以缓解相同问题?
设置可学习或固定的温度
使用 Additive(Bahdanau)注意力 ( MLP compatibility)
用一个小的前馈网络代替纯点积:
再 softmax。
为什么在进行多头注意力的时候需要对每个head进行降维?
多头自注意力机制是指将输入序列映射到ℎ个不同的子空间(设置
n_head=8,应满足n_head * d_k = n_model),在每个子空间中应用自注意力运算,将结果连接起来,进行一次线性变化融合注意力,再映射回原空间中。目的: 将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息。
- Transformer为什么不只使用一个头?
多头保证了transformer可以注意到不同子空间的信息,捕捉到更加丰富的特征信息,同时计算仍然可以并行化。单头注意力只在一个线性投影空间中计算注意力,只能关注一种关系(如仅关注语法或语义)。
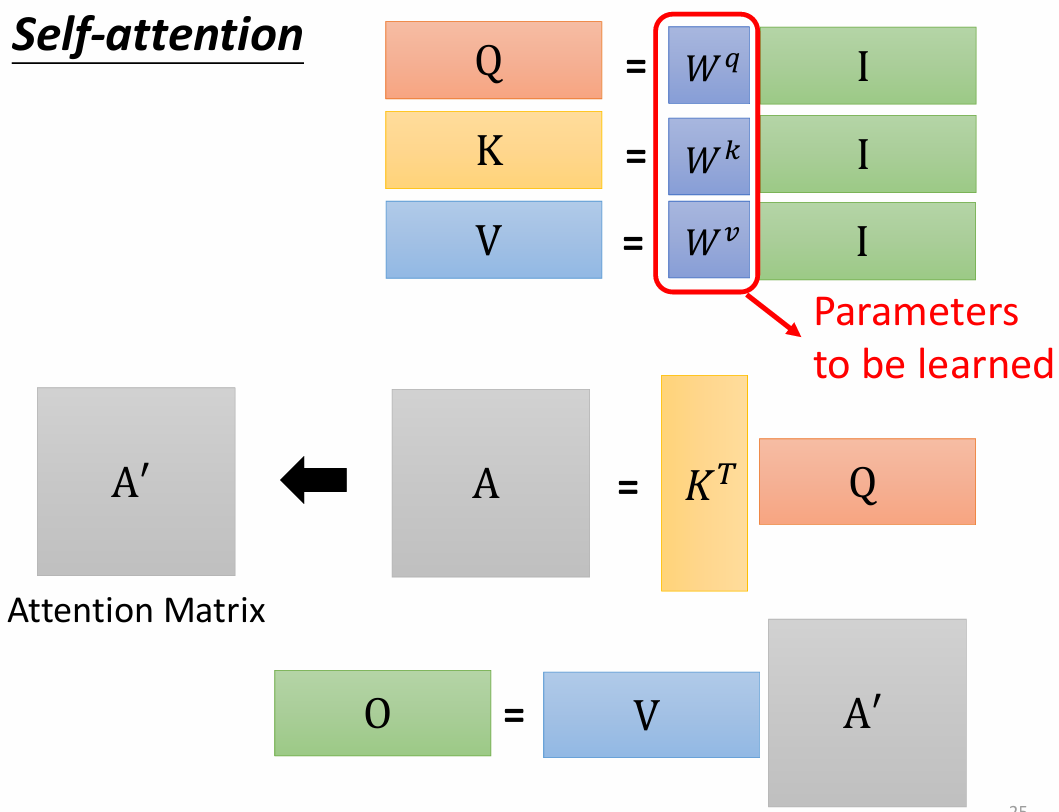
为什么Q和K使用不同的权重矩阵生成,为何不能使用同一个值进行自身的点乘?
如果 Q、K 使用同一个权重矩阵,那么 attention score 变成:
由于自相关项 qi⋅qi通常最大,Softmax 会把对角线项推到接近 1,从而得到一个接近单位矩阵的注意力矩阵:A≈I。此时每个 token 只关注自己,Self-Attention 退化成一种逐点线性变换,无法建模 token 之间的依赖关系。这样会导致Q 和 K 没有独立的“查询”和“键”的语义角色,严重限制注意力结构的表达能力。
计算attention的时候为何选择点乘而不是加法?两者计算复杂度和效果上有什么区别?
加性注意力(Bahdanau-style,Additive Attention)
缩放点积注意力(Scaled Dot-product Attention)
| 项目 | Dot-product | Additive |
|---|---|---|
| 核心操作 | 向量内积 | 小型前馈网络(MLP) |
| Q/K 维度要求 | 必须相同 | 不需要相同,被 MLP 投射到同一维度 |
| 参数量 | 只来自 W_Q, W_K(线性层) | 额外 W_q、W_k 和 v,参数更多 |
| 计算复杂度 | O(n^2*d_k),可用 GEMM 并行 | O(n^2d_a\((d_q + d_k))),常数因子大,不易并行 |
| 数值稳定性 | 高维下需除以√d | MLP 的 tanh 自带“压缩”效果,稳定 |
| 常见使用 | Transformer, GPT, BERT | RNN 注意力(Bahdanau, Luong) |
4. 残差连接和LayerNorm
残差连接
- Transformer 的残差结构的意义?
- 缓解深度网络的梯度消失
- 保留原始信息
- 训练更稳定,可堆叠更深层
LayerNorm
定义: 针对每个样本序列进行Norm,没有样本间的依赖。对一个序列的不同特征维度进行Norm
为什么transformer使用LayerNorm?
NLP领域认为句子长度不一致,并且各个batch的信息没什么关系,因此只考虑句子内信息的归一化,也就是LN。
LN对batch size不敏感: layernorm不需要再batch维度上计算均值和方差,所以不存在训练和推理的时候不一样的地方,不用保存一个全局的均值和方差供推理的时候使用
为什么transformer不用BatchNorm?
(1) 序列数据通常具有不同的长度,通过补0进行长度对齐。若在所有样本的某一个特征维度上进行标准化(BatchNorm),其计算得到的均值和方差变化较大,不利于存储滑动平均值。
(2) 序列长度变化, 所有样本的同一个特征维度没有相关性
BatchNorm技术优缺点?
优点:
(1) 减弱内部协变量偏移,抑制过拟合。简单来说训练过程中,各层分布不同增大了学习难度,BN缓解了这个问题。当然后来也有论文证明BN有作用和这个没关系,而是可以使损失平面更加的平滑,从而加快的收敛速度。(内部协变量偏移:在训练过程中,由于网络参数的不断更新,每一层的输入分布也会随之发生变化。这就像目标函数的地面在不断移动,使得网络需要不断地去适应新的分布,从而降低了训练速度,并可能使模型陷入不好的局部最优解(导致过拟合)。)
(2) 提高稳定性: 标准化将数据分布强制拉回到均值为 0,方差为 1的状态
(3) 缓解梯度饱和(梯度消失), 加快收敛: 对于 Sigmoid 和 Tanh 这样的激活函数,这个稳定区域(0 附近)恰好是它们的“非饱和区”或“线性区”,在这个区域,函数的梯度是最大的。缺点:
(1) batch_size较小的时候,效果差。BN的过程,使用整个batch中样本的均值和方差来模拟全部数据的均值和方差,在batch_size 较小的时候,效果肯定不好。
(2) 推理与训练统计不一致问题
RMSNorm是什么?优点?
RMSNorm 不减均值、不计算方差,只做均方根归一化:
d:特征维度
g:可学习的缩放参数→ 对每个特征维度分别乘上权重(与 LayerNorm 类似)
没有偏置项,也不减均值,计算更快
LayerNorm 的减均值步骤会引入额外的噪声和耦合项,深层大模型训练容易出现不稳定,RMSNorm 简化操作 → 梯度更平滑。
LLaMA/Qwen 都采用 Pre-LN 架构,RMSNorm 的稳定性更好。
LayerNorm 在 Transformer 中的位置?
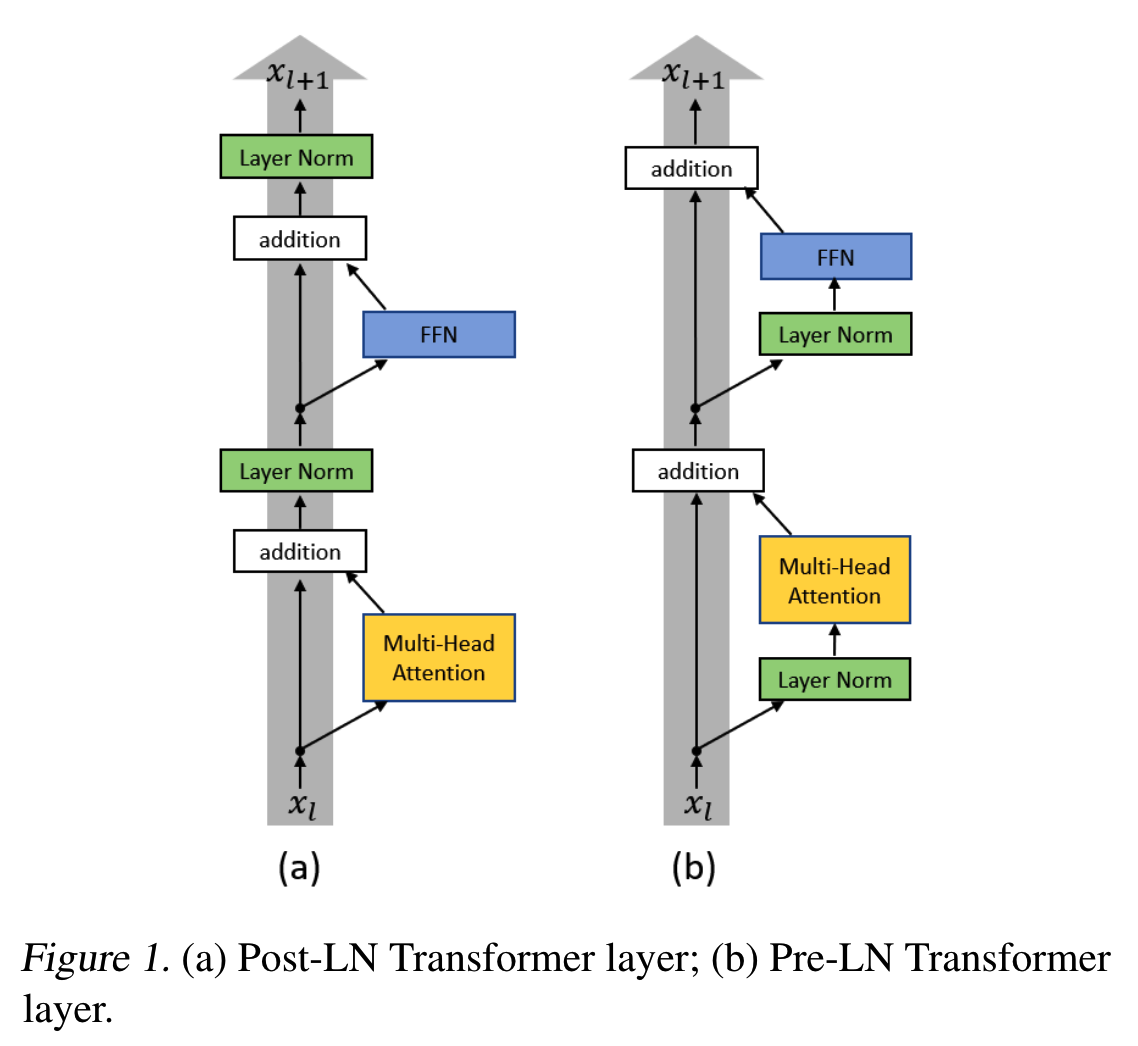
Pre-Norm更容易训练,因此可以叠加更多的层,但是在层数不是特别多的情况下,Post-Norm最终的收敛效果会比Pre-Norm要好
Pre-Norm
从模型结构上看,恒等分支永远有一部分不用经过normalization,这部分能够直接把梯度回传到最前面,这也是pre-norm能够训练“层数更多”的模型的原因—缓解了梯度消失。正常来说,模型深度对最终效果的影响,是大于模型宽度的。
Post-Norm (原始 Transformer)
post-norm在残差分支之后做归一化,对参数正则化的效果更好(loss平面更平滑),且它每norm一次就削弱一次恒等分支的权重,所以post-norm相对pre-norm,是更突出残差分支的,因此它的层数更加“足秤”,训练好之后效果更优。
5. Feed Forward Network
1 | class PositionwiseFeedForward(nn.Module): |
前馈神经网络层采用两层全连接层,全连接层作用于序列的每个位置,其中间特征维度为d_ff=2048。该层最后也使用了残差连接和Layer Norm:
激活函数通常使用 ReLU 或 GELU(BERT 用 GELU)
优点: 引入非线性, 扩大维度(如 2048)→ 提升表达能力
为什么transformer的self attention后要使用一个ffn?
自注意力负责捕捉序列的全局依赖关系,而FFN则通过非线性变换、局部特征细化及维度调整,进一步优化每个位置的表示。二者结合,使Transformer既能建模长距离依赖,又能深入挖掘局部特征,构成完整的特征处理单元。同时,《Attention Is All You Need》中,作者通过实验验证了FFN的必要性。移除FFN会导致模型性能显著下降。也是为了增加模型的容量。
二、 Decoder
解码器也由𝑁层模块堆叠而成(设置n_layers=6)。解码器采用自回归式的输入方式,即每次输入应为目标句子的一部分(右移shifted right的目标序列,初始为[START]),经过词嵌入后与位置编码相加。在实践中可以对解码器的输入序列进行mask,即对每一个输入token,在计算注意力时mask掉其后所有token,使得每一个输入token只能和其之前的输入token交互,通过这种mask机制可以在一次前向传播过程中实现所有自回归过程。
解码器的每层模块包含三个子层,即一个带掩码的多头自注意力层、一个多头自注意力层和一个逐位置的前馈神经网络层。其中带掩码的多头自注意力层将自回归mask应用到注意力计算中;多头自注意力层中的query来自前一个输出,key, value来自编码器的输出。
Encoder 和 Decoder 如何交互?
Decoder 的第二个注意力模块是 Encoder-Decoder Attention:
Decoder 使用自身的查询 Q,与 encoder 的 K/V 进行 cross-attention,从而利用 encoder 学到的语义信息。
Decoder 多头自注意力 vs Encoder 多头自注意力
Encoder self-attention:没有mask — 全部 token 可互相看到
Decoder self-attention:未来 token 必须 mask — 让输入序列只看到过去的信息,不能让他看到未来的信息(自回归)
Transformer 的并行化体现在哪?Decoder 能否并行?
Encoder:模块间串行,每个模块内的Attention和FFN完全并行(所有 token 同时处理)。
Decoder:
训练时可并行(因为 ground-truth 可用,SequenceMask就是为了并行化训练)
推理时 不能并行(下一个 token 必须基于当前结果)这是 Transformer 生成速度瓶颈的来源。
Transformer 训练时的学习率是如何设定的?
warm-up + inverse square root decay
学习率:
d_model:模型维度(如 512)
warmup_steps:预热步数(如 4000)前 warmup_steps 之前,学习率线性上升(Warm-up)避免模型初期梯度爆炸或发散。
warmup 之后,学习率按 step^{-0.5} 衰减 保证大模型训练稳定,防止后期震荡。
Transformer 使用 warm-up + inverse square root decay 学习率策略,前期升后期降,使训练更稳定,尤其适用于深层网络。
Transformer 中 Dropout 如何设定?位置在哪里?作用是什么?
Dropout 的位置包括:①嵌入层:embedding + positional encoding 后 ②残差连接前(Attention后、FFN后)③attention中:softmax后 ④FFN 中:激活函数后。典型值为 0.1。
推理阶段 Dropout 必须关闭。但权重会按保留概率(一般0.9)进行缩放,以保持输出期望值与训练时一致。
Dropout 的作用是防止过拟合、降低神经元之间的共适应(即固定依赖关系 co-adaptation,让不同特征不互相依赖,减少梯度陷入局部模式)、增强泛化能力、提高模型鲁棒性、类似集成学习效果(每次训练的是子网络)。
三、预训练语言模型(PLM)
根据 Transormer 模型的架构,预训练语言模型可以分为三类:
- 编码器(Encoder)型:仅包含Traneformer编码器部分,适合提取上下文表征(如BERT)。
- 解码器(Decoder)型:仅包含Transformer 解码器部分,适合自回归生成任务(如 GPT)
- 编码器-解码器(Encoder-Decodor)模型:结合编码器和解码器,适合序列到序列任务(如T5).
BERT: Bidirectional Encoder Representations from Transformers
模型架构:BERT 采用Encoder-Only架构
预训练过程(Pretraining):采用无监督学习,使用以下两种任务进行训练:
掩码语言模型(Masked Language Model, MLM) 在输入文本中随机掩盖部分词汇,模型需要预测被掩盖的词:
示例:Input:
The cat is [MASK] the mat.Target:on下一句预测(Next Sentence Prediction, NSP)
[CLS] sentense1 [SEP] sentense2训练模型判断两段文本是否为相邻句子,提高理解能力。
微调过程(Finetuning):BERT 适用于文本分类、命名实体识别、文本匹配等任务,通常将下游任务头(如分类器)添加到最后一层隐藏状态。
BERT 的 mask 为什么不用 Transformer 的 attention mask 技巧?
因为 BERT 的 mask 是输入级别的替换,模型要预测被遮盖 token,本质是 MLM 任务。
Self-attention 的 mask 用于:
隐藏未来信息(Causal Mask)
隐藏 padding
而 BERT 的 mask 是训练任务,不是 attention 结构上的遮蔽。二者目的完全不同。
GPT: Generative Pretrained Transformer
模型架构:GPT采用Decoder-Only 架构,使用单向自回归(Auto-Regressive)模型
预训练过程(Pretraining):采用自回归语言模型任务(Causal Language Modeling, CLM),即基于前面的文本预测下一个token:
示例:Input:
The cat is on theTarget:mat微调过程(Finetuning):GPT主要用于文本生成任务,如对话生成、摘要生成、代码生成等。
T5: Text-to-Text Transfer Transformer
模型架构:T5 采用 Encoder-Decoder 架构,结合了编码器和解码器。
预训练过程(Pretraining):T5统一NLP任务,将所有任务转换为文本到文本的形式。预训练采用以下任务:
- 文本填空(Text Infilling) 类似BERT的MLM,但可以掩盖连续多个token:
Input:The cat [MASK] the matTarget:is on - 去噪(Denoising Objective) 在输入文本中随机删除部分段落或单词,让模型恢复完整的文本。
- 文本填空(Text Infilling) 类似BERT的MLM,但可以掩盖连续多个token:
- 微调过程(Finetuning):T5 适用于多种文本生成任务,包括文本摘要、翻译、文本分类等。
CLIP: Contrastive Language-Image Pre-Training
CLIP → 图像 embedding + 文本 embedding
Transformer-Encoder结构
目的:图文对齐(语义对齐,跨模态理解)
训练任务:对比学习(Contrastive Learning)
1 | Image → CNN / ViT → Image Encoder ┐ |
参考文章:
https://0809zheng.github.io/2020/04/25/transformer.html
harvardnlp/annotated-transformer: An annotated implementation of the Transformer paper.
self-attention:
https://armanasq.github.io/nlp/self-attention/
https://magazine.sebastianraschka.com/p/understanding-and-coding-self-attention
autoencoder: