
大模型发展历程
1. 统计语言模型 (Statistical Language Model, SLM)
基于统计学习方法研发的统计语言模型,兴起于20世纪90年代。根据词序列中若干个连续的上下文单词来预测下一个词的出现概率,从而实现对自然语言的理解和生成。
代表模型:N-gram模型
应用场景
·输入法联想
·拼写纠错(teh—the)
·早期机器翻译(A一>B)
局限性
X数据稀疏问题(没见过的词组概率=0)
X上下文窗口极短(通常只看2-3个词)
2. 神经语言模型(Neural Language Model, NLM)
使用神经网络学习语言的概率分布。通过词嵌入捕捉词之间的语法和语义关系。常见架构包括RNN、LSTM和GRU,能更好地捕捉长距离依赖关系。”猫”[0.2,0.8…]代表模型:BNN-LM、word2vec
应用场景:
机器翻译/ 文本生成/ 语音识别
局限性:
X计算资源要求高(训练时间长)
X可迁移性差(需针对新领域重新训练)
3. 预训练语言模型(Pre-trained Language Model, PLM)
通过在大规模无标注文本上预训练的深度学习模型。核心思想:预训练一微调。先学习语言基本结构,再针对特定任务微调。代表模型:BERT、GPT-2、T5
大数据—模型(预训练一微调)——下游任务
应用场景:
文本分类/ 机器翻译/ 情感分析
局限性
X计算资源需求极高(训练成本巨大)
X训练数据含偏见(影响模型输出)
Pre-trained Models两大范式
1.浅层次嵌入(Non-Contextual Embeddings)
| 词嵌入 | 训练目标 | 预料范围 | 特点 |
|---|---|---|---|
| NNLM | 语言模型 | 局部语料 | 基于语言模型训练,词嵌入只是NNLM的一个产物 |
| Word2Vec | 非语言模型(窗口上下文) | 局部语料 | 采用分层SoftMax和负采样,损失函数为带权重的交叉熵 |
| Glove | 非语言模型(词共现矩阵) | 全局语料 | 全局语料构建词共现矩阵后进行高效矩阵分解算法 |
2.预训练编码器(Contextual Embeddings) (解决一词多义)
| 编码器 | PTMs代表 | 计算方式 | 特点 |
|---|---|---|---|
| MLP(MultiLayerPerceptron) | NNLM/Word2Vec | 前馈+并行 | 不考虑位置信息 |
| CNNs | 前馈+并行 | 考虑位置信息 n-gram局部上下文编码 | |
| RNN→LSTM | ELMo | 循环+串行 | 天然适合处理位置信息,但BPTT会导致梯度消失 |
| Transformer(Encoder) | BERT | 前馈+并行 | self-attention 解决长距离依赖,无位置偏差 |
| Transformer(Decoder) | GPT-1、GPT-2 | 前馈+并行 | |
| Transformer-XL | XLNet | 循环+串行 | 基于transformer引入相对位置编码 |
Recurrent NN
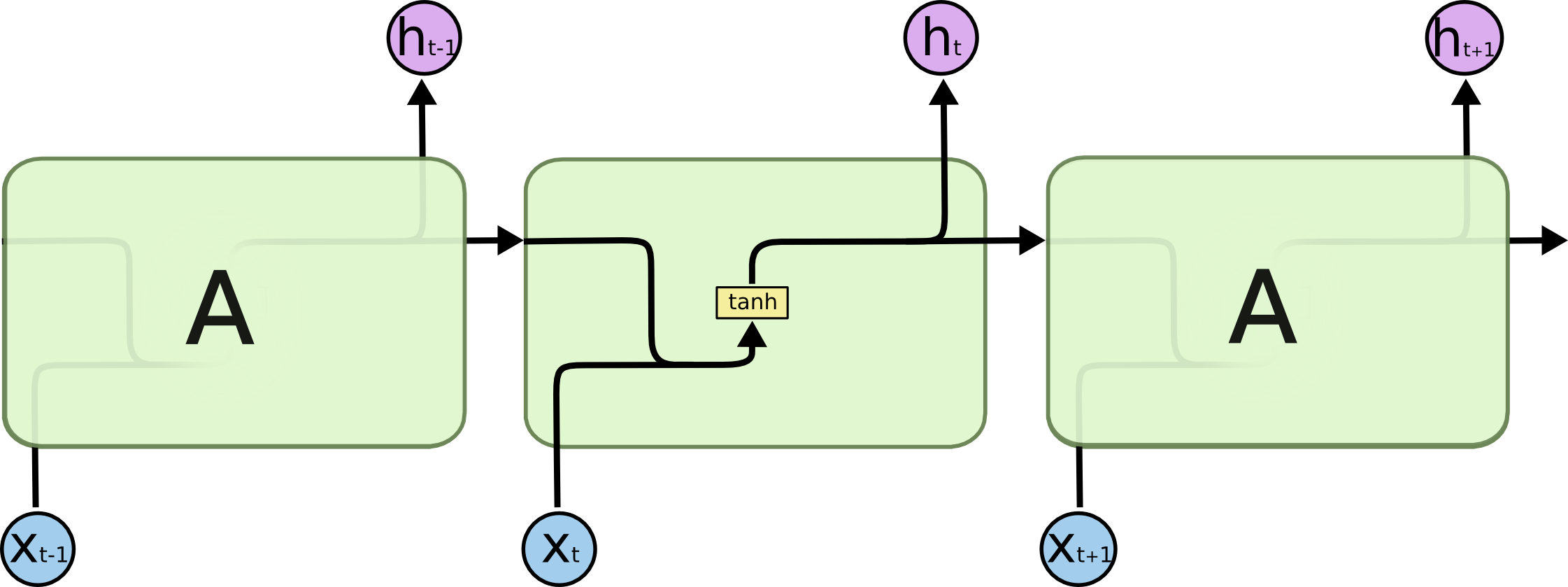
limitation:Vanishing gradient problem
Long Short Term Memory
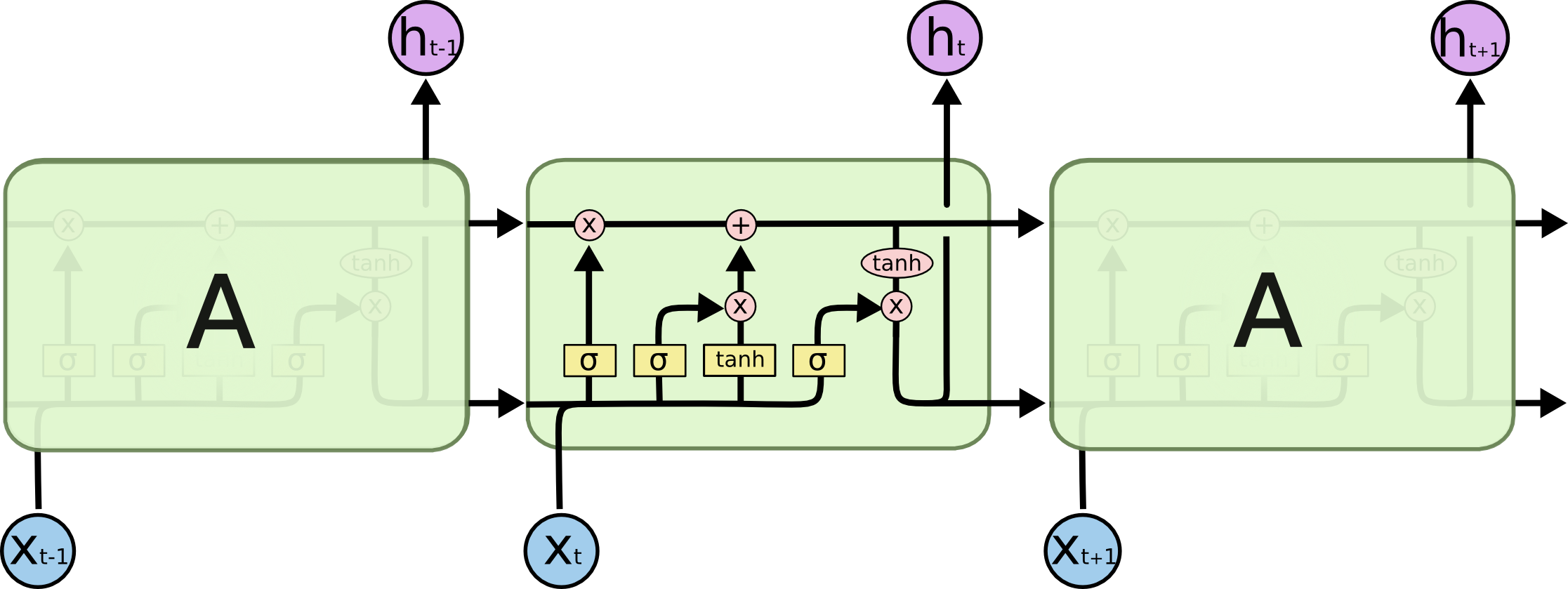
上侧箭头变化慢,下侧箭头变化快,保证梯度不会消失。
Embedding from Language Model (ELMo)
RNN-based language model
training of ELMo: Next Word Prediction
- contextualized word embedding
- each word token has its own embedding
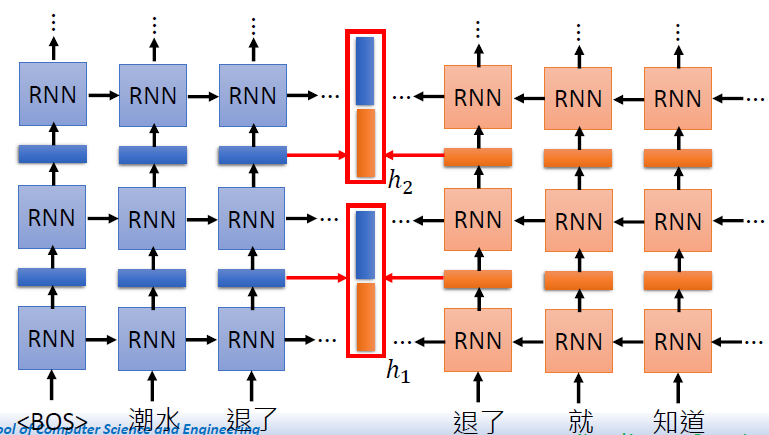
同一个单词上下文不同embedding可能不同(一词多义)
有从前到后和从后到前两种embedding,都要
有不同层的embedding, 都要,再给比例(不同实验比例不同)
Bidirectional Encoder Represtations from Transformer (BERT)
encoder of transformer
- bidirectional 双向!
Training of BERT
Approach 1: Masked LM (MLM)
盖掉句子中的一些单词,预测被改掉的单词是哪个
如果两个词汇填在同一个地方没有违和感,那么他们可能意思相似,拥有相似的Embedding
Approach 2: Next Sentence Prediction
判断两个句子是否应该被接在一起
[SEP] : the boundary of two sentences
[CLS] : the position that outputs classification results (一般在开头)
How to use BERT
根据特定 case对模型进行 fine tuning
case1: input 句子,output 分类(文本分类,情感分类)
经过BERT(fine-tuned)后, [CLS]的输出再来Linear Classifier。
case2: input 句子,output 每个单词的分类
case3: input 句子*2, output 分类 (根据前提,判断假设是否正确)
case4: Extraction-based Question Answering(给一篇文章,问他一些问题,问题中的词汇要在文章中出现过)
延申:Enhanced Representation through Knowledge Integration (ERNIE)
因为中文中盖掉一些字很容易猜出来,因此我们盖掉一些词汇。
Genrative Pre-Training (GPT)
decoder of transformer
非常非常的巨大,很神奇。
根据下游任务的模型修改
fine-tuning
预训练语言模型“迁就“各种下游任务。具体体现就是通过引入各种辅助任务loss,将其添加到预训练模型中,然后继续pre-training,以便让其更加适配下游任务,这个过程中,预训练语言模型做出了更多的牺牲。
delta-tuning
仅微调模型参数的一小部分,或是增加一组参数,而其余部分保持不变。
prefix-tuning
提出任务特定的trainable前缀prefix,这样直接为不同任务保存不同的前缀即可。只需要不同任务设置不同的Prefix即可,因此实现上只需要存储一个大型transformer模型和多个学习的任务特定的prefix参数。
prompt-tuning
将人为的规则给到预训练模型,使模型可以更好地理解人的指令的一项技术,以便更好地利用预训练模型。例如,在文本情感分类任务中,输入为”I love this movie.”,希望输出的是”positive/negative”中的一个标签。那么可以设置一个Prompt,形如:“The movie is _”,然后让模型用来表示情感状态的答案(label),如positive/negative,甚至更细粒度一些的“fantastic”、“boring”等,将空补全作为输出。
Part of speech tagging
- 词性标注
| Tag | Description | Tag | Description |
|---|---|---|---|
| CC | Coordinating conjunction | RB | Adverb |
| IN | 介词 | SYM | Symble |
| JJ | Adjective | VB | Verb |
| NN | None | DT | Determiner 限定词 |
4. 大语言模型 (Large Language Model, LLM)
是什么?
经过规模扩展的预训练语言模型,展现出”扩展法则”与”涌现能力”—能完成小模型无法胜任的复杂任务。本质是在海量无标注文本上预训练的超大型语言模型。数据预训练涌现能力代表模型:GPT-3、GPT-4、Claude
应用场景
对话系统/ 代码生成/ 文本生成
核心特点
扩展法则:模型越大,能力越强
涌现能力:超越小模型的突破性能力